












附录对于头结点单向链表的优化方法
720 字
4 分钟
附录对于头结点单向链表的优化方法
————————————本文旨在交流学习计算机知识,欢迎交流讨———————————
上一章,我们浅显的讨论了链表的结构,本文在上一章的链表的基础上做出了些许优化,可配合食用。
回到正题,我们已经了解链表的结构,它是一种非连续空间存储的线性表,主要依靠地址域访问下一个元素并通过遍历操作进行增删改查。
如图,这是我们上一章所介绍的链表结构:
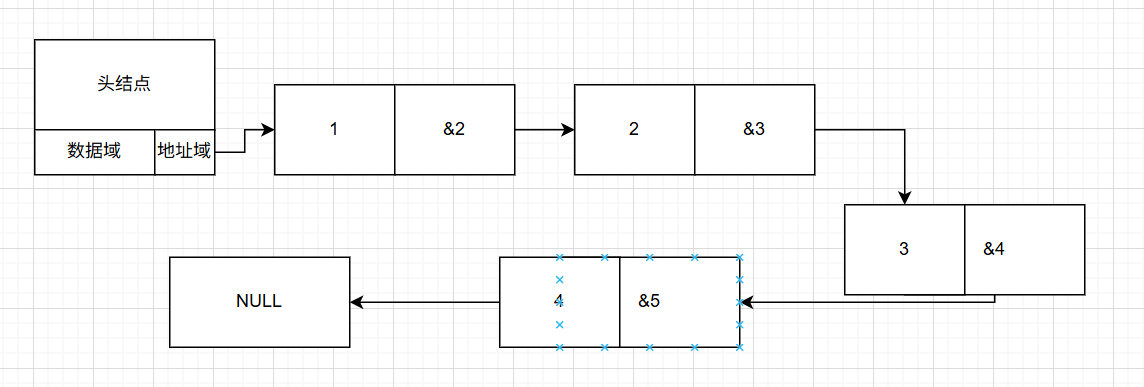 我们的惯用操作:
我们的惯用操作:
//单向链表的插入,删除(先找到节点p):
//插入:newnode->next=p->next;p->next=newnode;//删除:node_new temp;temp=p->next;p->next=p->next->next;free(temp);看着这幅图,我们不禁想到一个问题:我们真的需要这个头节点吗,是否有些看起来不整齐且结构不一致?于是,我们考虑到:也许我们可以用指针标记header的位置,然后再在每一次的函数接口里面新建一个头结点,用完即删,这样或许看起来更加的整齐和高效。
如图所示:
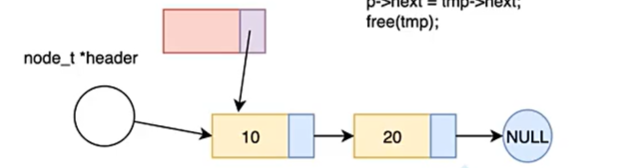 这时,我们引入dummy节点,并将其放入栈,dummy节点充当第一个节点。
这时,我们引入dummy节点,并将其放入栈,dummy节点充当第一个节点。
void insert(link*header,element val){node_t dummy;dummy->next=header;//header为我们的指针(因为简化了头结点,我们只传入指针)node_t *p=&dummy;//p为遍历指针,从dummy开始遍历;while(p->next){p=p->next;}header=dummy->next;//还原操作;}下面,我们重写一下代码: 定义链表结构:
typedef int Element_t;struct node{Element_t val;struct node *next;}node_t;//节点的结构体;
typedef struct {node_t *header;int count;} List_t;//链表结构体(包括头结点和数量);初始化链表:
void initList(List_t *table){table->count=0;table->header=NULL;)从最基础的展现函数开始:
void shouList(const List_t *table){node_t p=table->header;printf("List :");while(p){printf("%d\t",p->val);p=p->next;}printf("\n");}这里如果不知道const为什么要放在形参里的可以看看我的第一篇文章,里面有详细解答。 然后就是增删改查的经典案例了: 从增开始:
int insertListHeader(List_t* table,Element_t val){node_t dummy;dummy.next=table->header;
node_t *p=&dummy;//临时头结点dummy及临时过渡中间容器p;node_t *new_node=malloc(sizeof(node_t));
if(new_node==NULL){printf("ERROR\n");)//朴素的增加操作;new_node->val=val;new_node->next=p->next;p->next=new_node;++table->count;
table->header=dummy->next;return 0;}然后这是按位插入操作:
int insertListPos(List_t* table,int pos,Element_t val){if(postable->count){printf("the pos is not a truly place\n");}node_t dummy;dummy.next=table->header;node_t* p=&dummy;int index=-1;//计数器;while(indexnext;++index;}//遍历查找node_t *new_node=malloc(sizeof(node_t));new_node->next=p->next;p->next=new_node;++table->count;table->header=dummy.next;return 0;}删除操作:
int deleteList(List_t* table,Element val){node_t dummy;dummy.next=table->header;
node_t* p=&dummy;while(p->next&&p->val!=val){p=p->next;}if(p->next==NULL){printf("404 NOT FOUND\n");return 0;}node_t temp=malloc(sizeof(node_t));temp=p->next;p->next=p_next_next;free(temp);--table->count;table->header=dummy->next;return 0;}最后的最后就是销毁链表了 : ###关于销毁链表,其原理就是按位遍历并按位删除。###
void destroyList(List_t *table) {node_t dummy;dummy.next = table->header;
node_t *p = &dummy;node_t *tmp;while (p->next) {tmp = p->next;p->next = tmp->next;free(tmp);--table->count;}printf("LinkList have %d node!\n", table->count);// table->header = NULL;}以上就是附录内容,欢迎指正!
支持与分享
如果这篇文章对你有帮助,欢迎分享给更多人或打赏支持!
附录对于头结点单向链表的优化方法
https://firefly.cuteleaf.cn/posts/knowledge/附录对于头结点单向链表的优化方法/ 相关文章 智能推荐
1
拓展单向循环链表
数据结构 —————————————本文旨在讨论计算机知识欢迎指正——————————————— 书接上回:我们已经了解了链表如何编写与前置节点和头指针两种表示方式,下面,我们来了解进阶写法———如何实现单向循环链表。 下面,我们来梳理一下循环链表的实现方式: 这是朴素的链表实现形式:
这是我们理想中的循环...
2
链表的实现与介绍
数据结构 ——————————————本文旨在交流计算机知识,欢迎指正————————————— 首先,我们回顾一下上一期讲的顺序表: 顺序表是一种物理结构上连续的,一整块连续空间的逻辑表,但是,试想一下,如果每次我们都是申请在一块整块空间里面的顺序表,但是我们并不知道堆空间里面我们malloc一块空间之后我...
3
链表最终章双向链表及其应用
数据结构 ———————————本文旨在交流探讨计算机知识,欢迎交流指正———————————— 上一章,我们介绍了链表的循环扩展,但是,单向链表毕竟是单向查询的,就算是经过循环来查找,终究是效率偏低,下面,我们来介绍一种工程项目中运用更加广泛的一种链表结构:双向链表——:
根据此结构,我们可以发现,虽然代...
4
顺序表的实现与介绍及部分工程思想的思考
数据结构 ——————————本文旨在讨论和探究计算机知识,欢迎指正———————————— 首先,我们来聊聊什么是线性表: 线性表,顾名思义,是一种具有线性结构的数据排布形式 ,是一个类似数组的东西,在逻辑上一个接一个有序的整块链接,区别于链表的无序分布链接。
如图,我们可以得出,顺序表是一条线一样的结构...
5
数据结构之树及树的存储
数据结构 ——————————————本栏目旨在交流计算机知识————————————————— 上一章节,我们介绍了线性的数据结构:表,栈,队列。接下来,我们将进入下一章节——树结构的学习。 首先,我们先介绍一下树的基本概念: 结点:使⽤树结构存储的每一个数据元素都被称为“结点”。例如图中的A就是一个结点。...
随机文章 随机推荐
欢迎来到我的博客!这是一则示例公告。
音乐
暂未播放
0:00 0:00
33
7
25
56,127
0 天
0 天前