












链表的实现与介绍
——————————————本文旨在交流计算机知识,欢迎指正—————————————
首先,我们回顾一下上一期讲的顺序表:
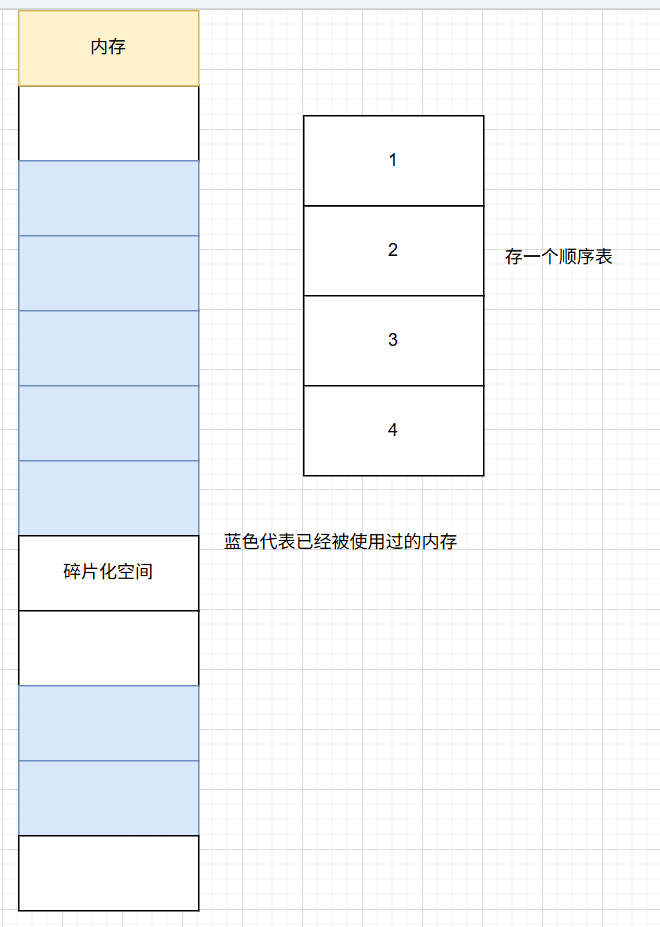
顺序表是一种物理结构上连续的,一整块连续空间的逻辑表,但是,试想一下,如果每次我们都是申请在一块整块空间里面的顺序表,但是我们并不知道堆空间里面我们malloc一块空间之后我们并不知道它的存储样式,假设我们申请了两段空间,但是这两块空间之间只有两个单位,但是我们要新存下四个单位的顺序表,那么这两个单位的空间显然装不下我们的顺序表,我们需要另外申请一块新的空间去存它,但是这些夹着的碎片化空间就会造成浪费,无法使用:
 于是,我们这时候需要一种新的结构去存储,来避免这种空间浪费的情况,链式存储结构应运而生:
于是,我们这时候需要一种新的结构去存储,来避免这种空间浪费的情况,链式存储结构应运而生:
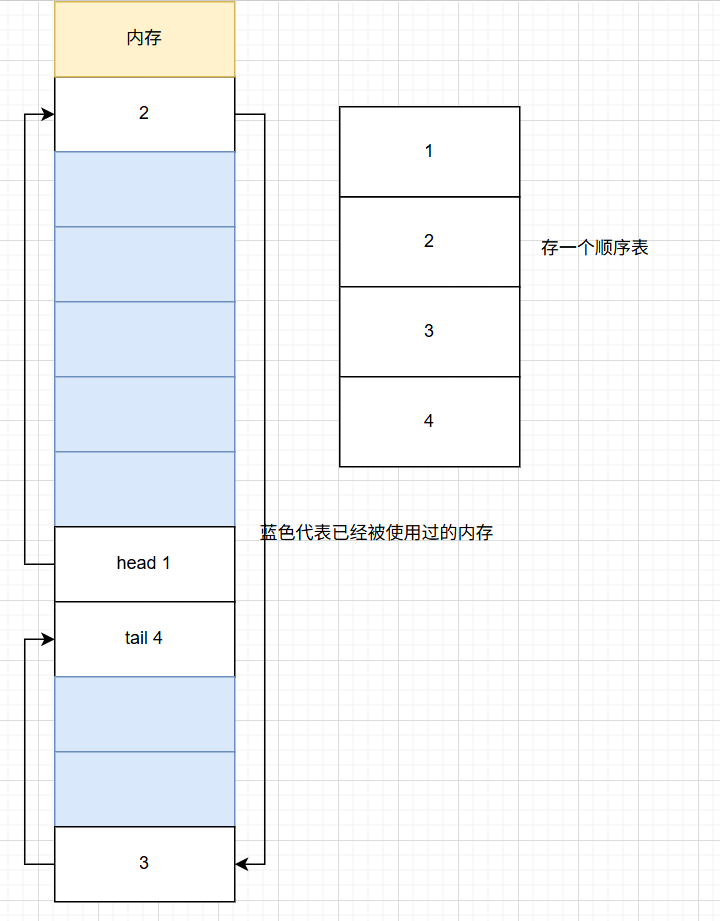 这样,我们就能理论上节约内存了;
这样,我们就能理论上节约内存了;

 (PS: 事实上,由于操作系统的存在,我们存储的只是在虚拟内存上,而它真实的内存其实映射到我们的物理内存上并非是如此的,于是对于顺序表操作系统给我们分配的物理内存其实并非真正连续的,我们这里讨论的其实只是无操作系统下关于内存的合理化分配)
下面,我们来详细讲讲关于链表的知识:
首先我们给出链表的图形化结构:
(PS: 事实上,由于操作系统的存在,我们存储的只是在虚拟内存上,而它真实的内存其实映射到我们的物理内存上并非是如此的,于是对于顺序表操作系统给我们分配的物理内存其实并非真正连续的,我们这里讨论的其实只是无操作系统下关于内存的合理化分配)
下面,我们来详细讲讲关于链表的知识:
首先我们给出链表的图形化结构:
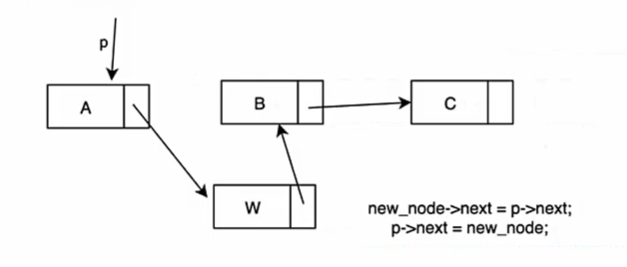 我们的链表包含一个头节点,一个尾部节点和数个中间节点,头结点的前驱是空,尾节点的后继也是空,中间节点都拥有前驱与后继。关于每一个节点,我们将其分为两个部分:1、数据域 2、地址域;数据域存储 该节点应该存储的数值,地址域指向下一个地址,然后我们通过地址域来访问下一个值。
我们的链表包含一个头节点,一个尾部节点和数个中间节点,头结点的前驱是空,尾节点的后继也是空,中间节点都拥有前驱与后继。关于每一个节点,我们将其分为两个部分:1、数据域 2、地址域;数据域存储 该节点应该存储的数值,地址域指向下一个地址,然后我们通过地址域来访问下一个值。

这样,我们就构成了一份链式存储结构;于是,下面我们来尝试写一下代码:
- 首先,和顺序表一样,我们先来定义链表的节点结构:
#ifndef COMMON_H#define COMMON_Htypedef int Element_t;// 1. 定义链表的节点结构typedef struct _node{Element_t val;//数据域struct _node *next;//存储下一个节点地址的地址域} node_t;
#endif //COMMON_H第二步,我们来写链表头结点的定义及函数的定义(如果对这里有所不明白的地方请翻到我的上一篇文章查看.h文件与.c文件的关系):
#ifndef CHAIN_LIST_H#define CHAIN_LIST_H#include "common.h"
// 2. 定义带头指针的链表头结构typedef struct {node_t *header;int count;} ChainList_t;
// 3. 链表头放到数据区,放到全局变量void initChainList(ChainList_t *table);
void destroyChainList(ChainList_t *table); // 销毁该链表的元素区域,头不管
int insertChainListHeader(ChainList_t *table, Element_t val);//头插法
int insertChainListPos(ChainList_t *table, int pos, Element_t val);//按位插入
int deleteChainListElement(ChainList_t *table, Element_t val);//按值删除
void showChainList(const ChainList_t *table);//显示链表#endif //CHAIN_LIST_H第三步,我们开始正式写函数啦: (一) 初始化函数
void initChainList(ChainList_t* table) {table->count = 0;//表头不计入元素个数table->header = NULL;//表头指向NULL}(二) 销毁链表函数
void destroyChainList(ChainList_t *table) {// 创建虚拟头节点,方便统一处理所有节点node_t dummy;dummy.next = table->header;// 从虚拟头节点开始遍历链表node_t *p = &dummy;node_t *tmp;// 逐个释放链表中的所有节点while (p->next) {tmp = p->next; // 保存当前要删除的节点p->next = tmp->next; // 从链表中移除该节点free(tmp); // 释放节点占用的内存--table->count; // 更新链表节点计数}
// 输出链表剩余节点数printf("LinkList have %d node!\n", table->count);// table->header = NULL;}(三) 头插法
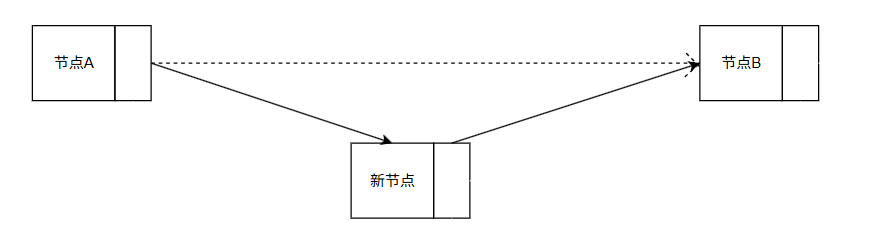
int insertChainListPos(ChainList_t* table, int pos, Element_t val) {node_t dummy;dummy.next = table->header;
// 1. 判断边界值if (pos table->count) {printf("insert pos invalid!\n");return -1;}// 2. 找到pos - 1索引的节点首地址node_t *p = &dummy;int index = -1;while (index next;++index;}node_t *new_node = malloc(sizeof(node_t));new_node->val = val;new_node->next = p->next;p->next = new_node;++table->count;
table->header = dummy.next;return 0;}(四)、删除操作
int deleteLinkListElement(LinkList_t* table, Element_t val){node_t *p = &table->head;//引入辅助节点while (p->next!=NULL){if (p->next->val == val)break;//如果当前辅助节点存储的值val等于删除目标,退出循环p = p->next;//辅助节点不断向后遍历}if (p->next == NULL)//判断是否有该值{return -1;}node_t *tmp = p->next;p->next = tmp->next;free(tmp);table->count--;//记录链表节点减1return 0;}(五)、展现函数
void showChainList(const ChainList_t* table) {node_t *p = table->header;printf("link list: %d\n", table->count);while (p) {//如果p存在printf("%d\t", p->val);p = p->next;}printf("\n");}(六)、 主函数(测试函数)
// 带头节点的单向链表测试int test01() {LinkList_t* table = createLinkList();if (table == NULL) {return -1;}for (int i = 0; i < 10; ++i) {insertLinkListHeader(table, i + 100);}insertLinkListPos(table, 3, 300);showLinkList(table);printf("========================\n");deleteLinkListElement(table, 105);showLinkList(table);
releaseLinkList(table);return 0;}
int main() {test01();return 0;}锵锵~到这里就要收尾啦!希望这篇文字对你有所帮助!
支持与分享
如果这篇文章对你有帮助,欢迎分享给更多人或打赏支持!
音乐
暂未播放