












顺序表的实现与介绍及部分工程思想的思考
——————————本文旨在讨论和探究计算机知识,欢迎指正————————————
首先,我们来聊聊什么是线性表:
线性表,顾名思义,是一种具有线性结构的数据排布形式 ,是一个类似数组的东西,在逻辑上一个接一个有序的整块链接,区别于链表的无序分布链接。
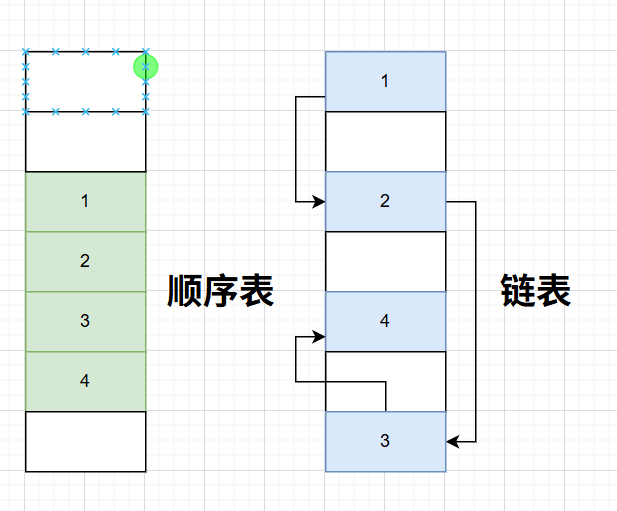 如图,我们可以得出,顺序表是一条线一样的结构,环环相扣,存在唯一的第一个元素(表头),也存在唯一的最后一个元素(表尾)。除了表头和表位,每个元素都有一个前驱和后继。
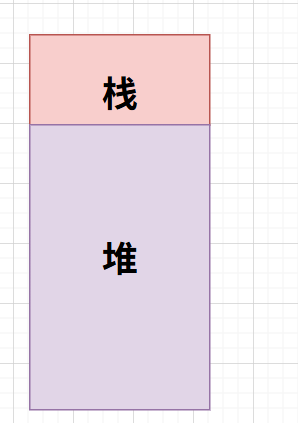
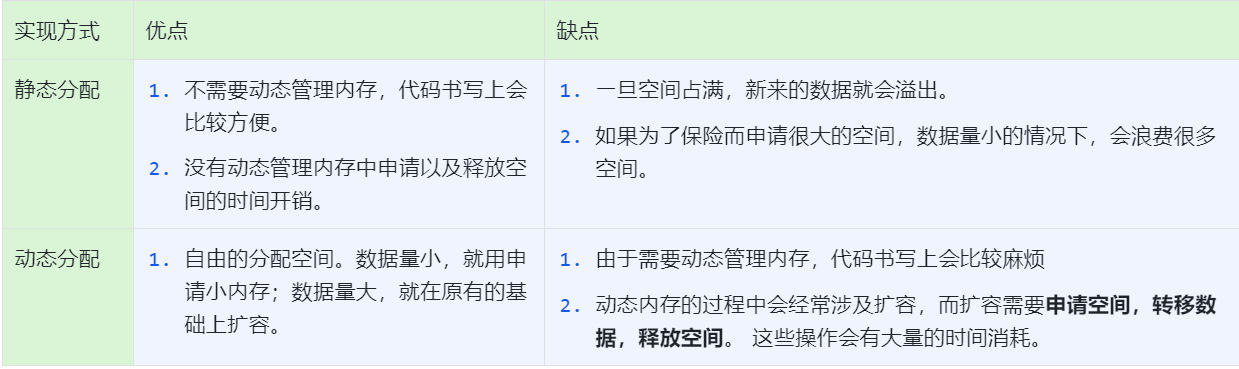
特别的,在c/c++里面,我们的数组就是一个很好的顺序结构,但是它是静态的,无法扩容和插入,这是因为数组是在栈空间里面实现的,所谓栈空间,就是申请后编译器自动分配的空间,这个空间是有限的,无法进行扩容,但是好在方便申请。
而我们今天讨论的就是在堆空间上实现的动态顺序结构:
所谓堆空间,就是程序员操作的空间,你可以在里面实现各种结构变化,扩容,插入等等…
如图:
如图,我们可以得出,顺序表是一条线一样的结构,环环相扣,存在唯一的第一个元素(表头),也存在唯一的最后一个元素(表尾)。除了表头和表位,每个元素都有一个前驱和后继。
特别的,在c/c++里面,我们的数组就是一个很好的顺序结构,但是它是静态的,无法扩容和插入,这是因为数组是在栈空间里面实现的,所谓栈空间,就是申请后编译器自动分配的空间,这个空间是有限的,无法进行扩容,但是好在方便申请。
而我们今天讨论的就是在堆空间上实现的动态顺序结构:
所谓堆空间,就是程序员操作的空间,你可以在里面实现各种结构变化,扩容,插入等等…
如图:
 下面,让我们开始顺序表的实现吧!
首先,我们要定义表头:
类似数组的结构,我们的顺序表是要在堆里面申请一块连续的空间。那么,这个空间的开始地址就很重要了。回顾数组,例如我们定义:
下面,让我们开始顺序表的实现吧!
首先,我们要定义表头:
类似数组的结构,我们的顺序表是要在堆里面申请一块连续的空间。那么,这个空间的开始地址就很重要了。回顾数组,例如我们定义:
int a[3]={0,1,2};printf("%d",a+1);//这时,会输出1的答案,那么a其实就是数组a的最开始的地址,类比表头有趣的是,我们在使用c++的STL工具时,vectorvc所定义的就是一个表头:
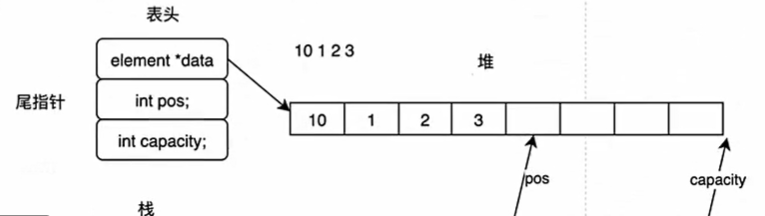
这里是我们定义的表头的结构体: 1、element 是一种重命名后的变量形式,它的好处在于我们typedef后如果某天发现数据存储形式错误,我们可以直接改element 而不是在每段每段的程序里面找和抠,极大减少了工作量。同时,Element_t也是工程里面常用的一种 定义模式,“_t”有种正确规范的意味。 2、pos是我们动态的“数据个数”,也是“下一个是第几个数据”,方便定位,极大优化了查找效率。 3、capacity 是顺序表空间的容量个数,表征最多存的数量,扩容的时候常用。 代码实现:
typedef struct {Element_t *data; // 存储表中数据空间的首地址int pos; // 指向数据空间的待插入的位置,也是空间里数据个数的表示int capacity; // 表中目前最大的存储容量} SEQTable_t;下面,我们讲讲工程思想: 一般的,我们在写代码的时候,总是一股脑的把所有函数和代码放在一个文件里面,但是这样对多文件编程和重复调用很不友好,我们得每次使用都在子函数里面在写一遍,很麻烦且容易错,下面本文将简单介绍一下常用方法:
- 关于多文件编程,我们可以做到如下几点,来使得函数在同一个文件夹内协同作用:
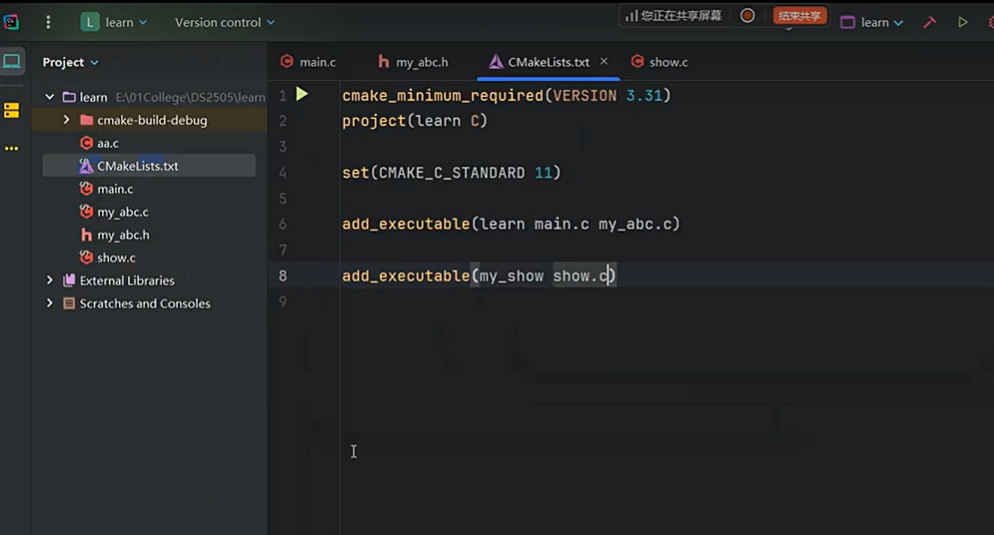
以上是用clion软件为例,在CMakeLists.txt中的add_executable()里面加上你希望一起需用的文件名,就可以使用了;当然,这里我们的前导是文件打开的文件夹的名字:

add_executable**:这是 CMake 的内置命令,作用是告诉 CMake 要创建一个可执行文件。seqTable:此为可执行文件的名称,编译完成后,在构建目录下会生成名为seqTable(Windows 系统下是seqTable.exe)的可执行文件。01_seqTable/main.c:表示源文件的路径,这里指明使用01_seqTable目录下的main.c文件来编译生成可执行文件。
如果你要使用中文,但是你用的是Windows系统,记得把UFT-8改为GBS国标,由于编译方式的不同,会出现乱码。(Linux和Mac不会有这种问题) 2、头文件的类编写: 如果在一个文件夹下我们进行头文件.h的编写,那么下次使用(在文件夹内)我们就可以直接用头文件里面的东西了,而不用在main.c文件里面再写一遍。 有些人可能会想一个疑问:既然.h文件里面可以编写结构体而且能直接被.c使用,为什么不在.h的文件里面编写函数,这样不是更方便吗?回答:我们不要把.h和.c看成两部分,也不要只认为.h只在.h的目录下实现。因为——.h只要能被编译器读到,那这个.c就可以被正常编译,所以.h放哪里都可以,只是要告诉编译器这个.h在哪里。一般像gcc有-I选项,VC那块可以右键属性添加查找头文件路径的。 .h相当于是一个显性目录的作用,.c是我具体实现的代码,我可能不想公开给别人,但是别人想用我的函数,我就告诉他我函数的申明,然后我把.c编译成动态库给他。就像printf那样,你根本就不知道咋实现的,但是可以轻松使用它。我们在#include “a.h“的时候,没有前缀,直接写a.h就表示在当前目录下查找是否有这个文件,只要头文件能找到,就可以直接用函数了。 这是一个顺序表的.h文件的实现:
//// Created by 水木 on 25-5-30.//
#ifndef SEQ_TABLE_H#define SEQ_TABLE_H
//定义一个数据空间存储类型typedef int ElemType_t;//这里尾部加上_t指的规范的重命名数据类型;
typedef struct {ElemType_t *data;//首地址int pos;//待插入位置int capacity;//最大存储容量}SEQTable_t;
//表头在堆上申请,提供给其他函数使用,需要释放的接口;SEQTable_t *createSeqTable(int n);//申请内存void releaseSeqTable(SEQTable_t *table);//释放内存
int pushbackSeqTable(SEQTable_t* table, ElemType_t val);//尾插法
static int enlargeSeqTable(SEQTable_t *table);//扩容
int insertPosSeqTable(SEQTable_t *table, int index, ElemType_t value);//中间插入
int findSeqTable(const SEQTable_t* table, ElemType_t val);//找寻函数
void deleteSeqTable(SEQTable_t* table,ElemType_t val);//删除函数
void ShowSeqTable(const SEQTable_t *table);//此时用静态变量
#endif //SEQ_TABLE_H下面,我们回到顺序表的实现上来 : 首先,我们实现申请表头的函数:
SEQTable_t *createSeqTable(int n) {SEQTable_t* table = NULL;table = malloc(sizeof(SEQTable_t));if (table == NULL) {fprintf(stderr,"SeqTable malloc defeat!\n");//申请失败,释放表头return NULL;}table->data = malloc(sizeof(ElemType_t)* n);if (table->data==NULL) {fprintf(stderr,"SeqTable data malloc defeat!\n");free(table);//申请结构体内数据数组空间失败,释放表头return NULL;}table->pos=0;//初始化pos;table->capacity=n;//初始化capacityreturn table;}有了表头,就要有释放函数:
void releaseSeqTable(SEQTable_t *table) {//如果有表头空间就释放if (table) {//如果有数据空间就释放if (table->data) {free(table->data);}free(table);}}下面,我们来实现增删改查: 首先,是增:
//这里使用static有好处,是静态继承的,只会在内部改变,不会因为外界干扰而紊乱,增加安全性static int enlargerTable(SEQTable_t *table) {// 1. 再申请一个新空间,初始化申请的空间Element_t *tmp = malloc(sizeof(Element_t) * table->capacity * 2);if (tmp == NULL) {printf("enLargerTable malloc failed!\n");return -1;}// 2. 拷贝老内容到新空间,for循环一个个拷贝,直接空间拷贝memcpy(tmp, table->data, sizeof(Element_t) * table->pos);//string.h下的函数memcpy(空间名,赋值位置,赋值个数*单位大小=总体积)// 3. 更新表头,释放老空间table->capacity *= 2;//两倍扩容是一个习惯性行为free(table->data);//释放原空间table->data = tmp;//将原空间指针指向现有空间
return 0;}//特别的,空间扩容是先创建一个副本再copy上去,最后释放空间,为防止空间泄露,所以不在原来空间上扩容(可能原来空间的下面几个空间已经被分配给其他板块,如果在原空间上强项扩容可能导致其他版块数据丢失,程序崩溃)
int pushbackSeqTable(SEQTable_t* table, ElemType_t val) {if (table == NULL) {fprintf(stderr,"SeqTable malloc defeat\n");//排除表头不存在的时候增return -1;}//这里是集成了扩容函数enlaegeSeqTable(table)的增添,如果满了的条件下就增,否则跳过不判断,扩容函数返回0的时候是扩容成功所以&&满足true的时候输出扩容失败:if (table->pos>=table->capacity&&enlaegeSeqTable(table)) {printf("badbad,cant enlarge place!\n");return -1;}table->data[table->pos]=val;//赋值,扩容成功++table->pos;//pos右移,指向下一个return 0;}其次,是删和查的实现:
int findSEQTable(const SEQTable_t *table, ElemType_t val) {for (int i=0;ipos;++i) {if (table->data[i]==val) {return i;}}return -1;}//删查一体,查找到了才能删;
int deleteSeqTable(SEQTable_t* table, Element_t value) {// 1. 查找value在数据结构中的索引位置int index = findSeqTable(table, value);//未找到则输出“Not find %d element!”if (index == -1) {printf("Not find %d element!\n", value);return -1;}// 2. 删除这个元素,把[index + 1, pos) 搬移覆盖到,把后一个给前一个for (int i = index + 1; i pos; ++i) {table->data[i - 1] = table->data[i];}--table->pos;return 0;}最后,是改的实现(插入):
int insertPosSeqTable(SEQTable_t* table, int index, Element_t value) {// 1. 空间有效性的判断if (index table->pos) {printf("index Invalid!\n");return -1;}// 顺序表进行扩容if (table->pos >= table->capacity && enlargerTable(table)) {printf("....\n");return -1;}// 2. 搬移数据为新数据预留位置 从后往前 data[i + 1] = data[i];// [pos-1, index] 使用for --操作for (int i = table->pos - 1; i >= index; --i) {table->data[i + 1] = table->data[i];}table->data[index] = value;++table->pos;
return 0;}噢,对了,还有一个展现函数:
void showSeqTable(const SEQTable_t* table) {if (table == NULL) {return;}//没有表,没有展现的
for (int i = 0; i pos; ++i) {printf("%d\t", table->data[i]);}//制表符\t,看起来更整齐
// deleteSeqTable(table, )printf("\n");}下面,是我们的测试函数,在main.c里面测试:
void test01() {SEQTable_t *table01=createSeqTable(10);if (table01==NULL) {return;}for (int i=0;i<5;i++) {pushbackSeqTable(table01,100+i);}for (int i=5;i<10;i++) {insertSeqTable(table01,i-2,100-i);}showSeqTable(table01);releaseSeqTable(table01);}
int main() {test01();return 0;}顺序表的总结:
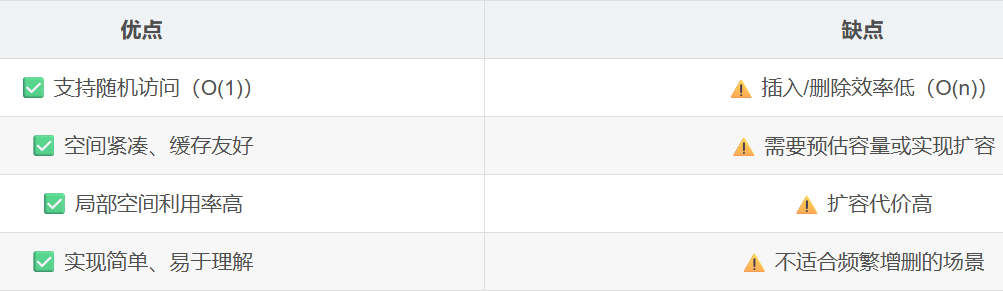 希望对您有所帮助!
——————————————————欢迎指正————————————————————
希望对您有所帮助!
——————————————————欢迎指正————————————————————
支持与分享
如果这篇文章对你有帮助,欢迎分享给更多人或打赏支持!
音乐
暂未播放